最近的一个网站项目是制作集团的官网,开始的时候是一起写了静态页面,之后又和同事一起套了onethink的模版页面.用的是公司内部整理的kconethink系统,基于onethink自己做了一些内部的扩展和相关的优化,在制作这个项目的过程中,也是多人合作开发,其中也遇到了不少的问题,正是由于客户的需求不断改变,有不少问题需要考虑,也让自己对这个系统更加的熟悉,学习到了更多的内容.onethink是基于thinkphp写的,其实根本还是得我们熟悉thinkphp的语法和相关基础知识,才能运用的顺手.
公司内部自定义插件
首先,公司内部自己自己扩展了不少的插件和钩子,有导航高亮,百度地图,ajajx分页插件等等.此次制作该官网,页面相关的要求倒是不少,同时要兼容手机端,而且还是双语切换,瀑布流效果等,分页效果基本上都是ajax分页插件实现的(也就是同事@qiang写ajax分页插件).不过在使用的过程中也还是遇到了不少的问题.记忆特表深刻的就是那个瀑布流效果和新闻列表页面的描述截取. 下面整理一下在这个项目中遇到的相关基础知识,进行相关的笔记记录: 1.项目中相关目标文件的配置信息,我们可以在分类管理中,点击编辑进行相关的配置:(如下图)
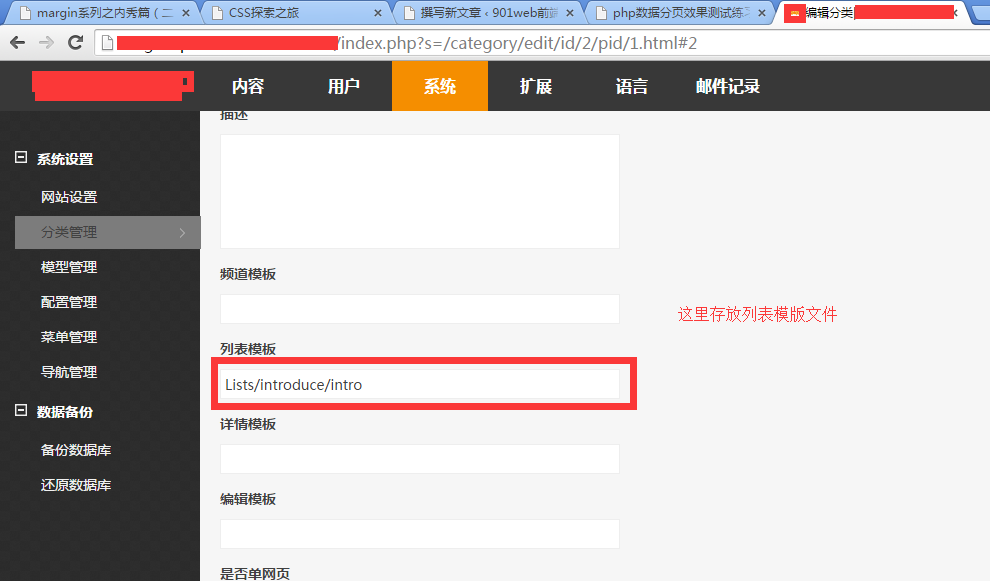
另外就是导航链接的相关配置,当有二级菜单的时候,我们直接进入二级菜单的第一个子菜单页面.(这里就需要进行相关的链接配置).并且在有二级菜单的选项时候,我们点击对应的栏目进入还要添加对应的二级菜单栏目.(点击的地方是后台的导航管理里面,在对应有二级菜单的地方进行加)
其次是导航栏目的调用部分代码: ##导航栏目部分做的相关判断:
<think:nav name='nav' tree='true'>
<li>
<a href="<if condition='!$nav[_]'>{:get_nav_url($nav['url'])}<else/>javascript:;</if>" class="<eq name='key' value='0'>smenu1</eq> snav" child="{:getChildUrl($nav['_'])}">
<span>{$nav.title}</span>
<notempty name='nav["_"]'><i class="icong"></i></notempty>
</a>
<notempty name='nav["_"]'>
<div class="sub_menu">
<div class="submenuContainer">
<ul>
<volist name="nav['_']" id="sub">
<li><a href="{:get_nav_url($sub['url'])}">{$sub.title}</a></li>
</volist>
</ul>
</div>
</div>
</notempty>
</li>
</think:nav>
注意事项
另外值得注意一点的是,当有二级下拉的子菜单的时候,点击导航管理,点击对应的导航栏目进去需要继续添加对应栏目的二级菜单,我自己再弄的时候确把这个给搞忘记了...^^^^^^ 另外感觉有一个感觉比较实用的功能就是新建相关的模型,其中有基于文档的模型和独立模型两种,其中可以根据自己的需求建立相关的模型,当新建立了模型后,数据库中就增加了相关对应的数据表,然后我们可以根据模版页面中所需展示的数据来添加对应的字段. ##模型管理里面,当新增模型的时候需要填写的列表定义部分
id:编号
title:标题:article/edit?cate_id=[category_id]&id=[id]
type:类型
update_time:最后更新
status:状态
view:浏览
id:操作:[EDIT]&cate_id=[category_id]|编辑,article/setstatus?status=-1&ids=[id]|删除
模版中进行相关的判断规则:
<if condition="$res[group] eq 1">
11111
<else/>
2222222
</if>
判断:(标签循环的时候添加判断)
<if condition="($key+1)%4 eq 0">class='list last'<else/>class='list'</if>
前台模版中对标题,描述中的html代码相关转义函数使用:前{$content|htmlspecialchars_decode} 前台模版中调用相关的截取函数:{$res.description|msubstr=0,60,'utf-8',true} @zhouzhiqiang修改了ot标签自带的<think:article>标签,使其支持传递参数catename值.
在读取数据的时候,有时候程序没有问题,但是读取的数据条数不对头,这是我们可以查看下查询的条件,看看是否读取了回收站中的数据,对回收站中的数据进行一遍过滤.
网信金融官网邮件发送记录(新建独立模型): 根据相关模板页面中的表单字段进行,在后台直接建立独立模型,然后点击导航栏目的 "系统->左侧菜单管理->新增邮件记录栏目" 然后填写相关的标题和链接. (如果不填写新建独立模型下面的列表定义的话,点击进去就没有进行相关的操作和记录,如果是建立基于文档模型的,如果不填写则无法提交).
点击菜单管理,点击进入邮件记录,进行新增菜单,将会在左侧菜单栏显示. 并且在新建立相关模型的时候,列表定义相关规则关系着相关模型数据的展示. 纠结蛮长时间的还是在处理瀑布流那块.我自己测试的时候,数据加载出来了.
但是就是没有应用上jquery.masonry.min.js插件的效果,最后还是同事修改了ajax分页插件,将数据在解析出来之后进行了处理.才应用上瀑布流效果... 最后新闻列表以及其他ajax分页数据显示部分的截取函数格式写法: 最外面的一层div要添加ajax_data_box的类名. 其次要写上:
<div class="single ajax_data_lists" style="display:none;">
<div class="thumb">
<img src="" class="addons_ajax_titlethumb" pos="titlethumb:src" alt="" style="max-width:198px">
</div>
<div class="text">
<h2><span class="time addons_ajax_create_time">{$res.create_time|date="y-m-d",###}</span><a href="" class="addons_ajax_title addons_ajax_url" pos="url:href">标题</a><img src="" class="addons_ajax_logo" pos="logo:src" width="74" height="30"/></h2>
<p class='addons_ajax_description'>简介</p>
</div>
</div>
<div class="pages">{:Hook('ajaxPage',array('cate_id'=>47,'fields'=>'title;description|msubstr=###,0,100;create_time|date=Y-m-d,###;titlethumb|get_cover_path_thumb;logo|get_cover_path_logo;__DOCUMENT.id as url|getDetailUrl','listRow'=>5,'order'=>'level desc,create_time desc','name'=>'dynamic'))}
<div class="ajax_data_page"></div>
</div>
thinkphp自带截取字符串函数修复(fixed):
function msubstr($str, $start=0, $length, $charset="utf-8", $suffix=true) {
if(function_exists("mb_substr")) {
if($suffix)
{
if($str==mb_substr($str, $start, $length, $charset))
{
return mb_substr($str, $start, $length, $charset);
}
else
{
return mb_substr($str, $start, $length, $charset)."...";
}
}
else { return mb_substr($str, $start, $length, $charset); } }
elseif(function_exists('iconv_substr')) { if($suffix) {
if($str==iconv_substr($str,$start,$length,$charset))
{ return iconv_substr($str,$start,$length,$charset); }
else{ return iconv_substr($str,$start,$length,$charset)."..."; }}
else {
return iconv_substr($str,$start,$length,$charset); } }
$re['utf-8'] = "/[\x01-\x7f]|[\xc2-\xdf][\x80-\xbf]|[\xe0-\xef][\x80-\xbf]{2}|[\xf0-\xff][\x80-\xbf]{3}/";
$re['gb2312'] = "/[\x01-\x7f]|[\xb0-\xf7][\xa0-\xfe]/"; $re['gbk'] = "/[\x01-\x7f]|[\x81-\xfe][\x40-\xfe]/";
$re['big5'] = "/[\x01-\x7f]|[\x81-\xfe]([\x40-\x7e]|\xa1-\xfe])/"; preg_match_all($re[$charset], $str, $match);
$slice = join("",array_slice($match[0], $start, $length));
if($suffix) return $slice."…";
return $slice;
}
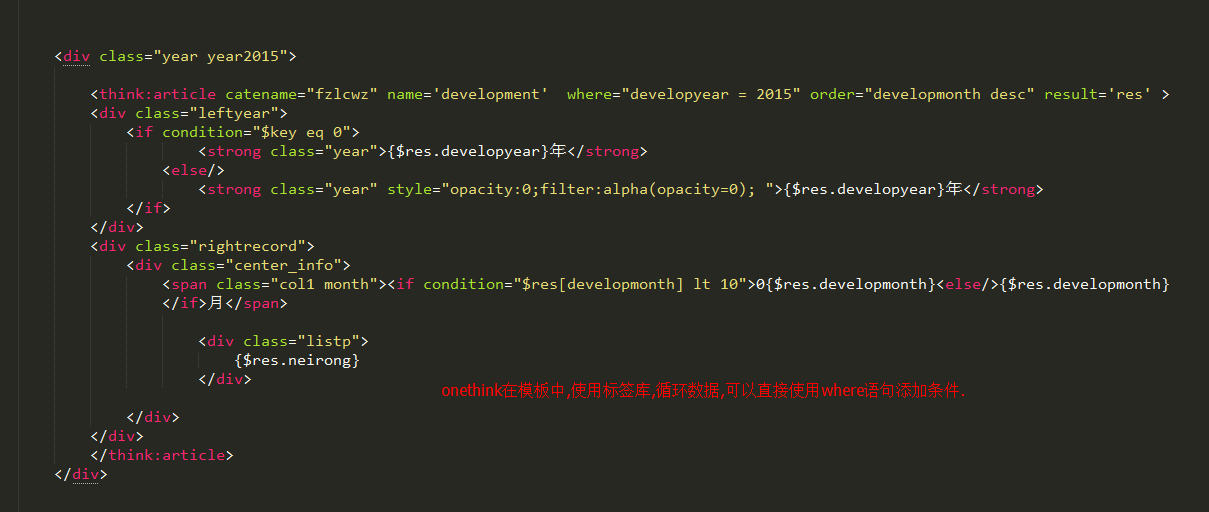
模板标签中,标签库中使用where条件
<div class="year year2015">
<think:article catename="fzlcwz" name='development' where="developyear = 2015" order="developmonth desc" result='res' >
<div class="leftyear">
<if condition="$key eq 0">
<strong class="year">{$res.developyear}年</strong>
<else/>
<strong class="year" style="opacity:0;filter:alpha(opacity=0); ">{$res.developyear}年</strong>
</if>
</div>
<div class="rightrecord">
<div class="center_info">
<span class="col1 month"><if condition="$res[developmonth] lt 10">0{$res.developmonth}<else/>{$res.developmonth}</if>月</span>
<div class="listp">
{$res.neirong}
</div>
</div>
</div>
</think:article>
</div>